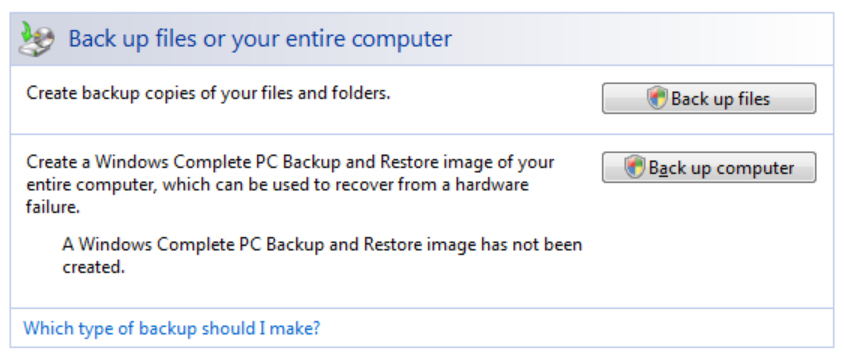
Recently the hard drive on which I had Vista installed began to behave erratically. But I wasn’t worried as I had been using Vista’s “Complete PC Backup”! What could possibly go wrong? However, try as I might, and I tried a lot, I wasn’t able to get the recovery to work. It always gave the same error message, “There are too few disks on this computer or one or more of the disks is too small.”
My trouble was caused by the fact that I wanted to replace my drive. The “Complete PC Recovery” works if all you want to do is to rollback to an earlier backup. It seems that Vista’s “Complete PC Backup” is not designed to help if your hard drive dies.
Perhaps the use of the word “complete” here is a little too strong.
I cobbled together this fix after reading a thread in the Microsoft Technet Forum.
Boot from the install DVD, click “Next”, “Repair…”, and then “Next”.
You should be at a dialogue box titled “System Recovery Options”, select “Command Prompt” (ignore “Windows Complete PC Restore”).
Use the command diskpart to setup your new drive. The use of diskpart is well documented in the forum thread mentioned above, or at many other places on the Web. If your target drive is not already formatted, then you’ll have to use diskpart to do that. The commands you’ll need to issue will most likely be different for your setup, but it basically goes something like this: list disk, select disk 0, clean, create partition primary, list partition, select partition 0, format quick. Now, I’m not sure if the following was necessary, and it’s something you may also want to do even if your drive is already formatted. I issued the command assign letter c whilst I had the new volume selected. In any case you’ll need to know the drive letter of your target volume. Once you’re finished, type exit to leave diskpart.
Now, issue the command: wbadmin get versions -backupTarget:e: …substituting the drive letter of your backup drive, and copy the latest version string returned.
Next, issue the command: wbadmin start recovery-version:12/23/2008-16:39-itemtype:volume-items:c:-backuptarget:e:-recoverytarget:c: …substituting the necessary drive letters and version string. (Thanks to AtomicInternet for the command.) This is where assigning the current drive letter of “c” to the target drive saves some confusion.
Once it’s done return to the list of “System Recovery Options” and choose “Startup Repair”. This will rebuild the boot-sector of the recovered drive.
Notes:
If you are using this to move to a smaller drive, and still have the original volume available, you can dynamically shrink the partition from within Vista before running a backup. (You use “Computer Management” to do this.) This may be necessary even if you think the two drives are the same size (for example, not all 500GB drives are identical in size). If the drive sizes differ by only a byte, the restore will fail.
Contrary to the claims of others, it does not matter how your drives are interfaced for this method to work. It makes no difference if your drives are hooked up via USB, IDE or SATA. Even if one or both of your drives are moved from one interface to another between backup and restore, it will still work.
Contrary to the experience of others, I did not have to re-authenticate my OEM copy of Vista. (In fact I’ve changed my CPU, RAM, video card, sound card and optical drive, all in addition to my hard drive, and I haven’t had to re-authenticate.)
What follows are the results from an experiment I conducted over several days during April of 2004 to determine which of four SETI@home clients was the fastest at processing work-units. The results should be considered as weak due to the large number of variables, the small sample taken and the limited scope of the experiment. The four clients, ordered fastest to slowest as I found them, are:
Also, under typical workstation installations, I found a significant amount of variation in the time taken for the same client to process the same work-unit. This implies that there is significant room for optimisation in the case of a dedicated SETI@home computer.
Review
A search of the Web revealed two major lines of thought.
The Linux client is slower except when processing VLAR units, and since these units occur infrequently, the Windows client is generally faster. (This assertion was often made with no reference to the version number.)
Version 3.03 is faster than 3.08. (This assertion was often made without reference to the platform.)
What I did not find was evidence that tied these two assertions together. Hence my motivation for this experiment.
Aim
I wanted to find which of the clients was generally the fastest at processing units.
Design
The main difficulty in this experiment is that every work unit is unique and hence requires a different amount of processing time. The best practice in this case would be to run each client a large number of times and find the mean time taken. However each work unit takes several hours to complete and time was limited so I needed another approach.
For each run I decided to use the work-unit contained within amdmb-bench.zip that I obtained from seti.amdmbpond.com. It is described as a typical work-unit and is widely used as a benchmarking tool. This unit is not a VLAR (very low angle range) unit. VLAR’s generally take longer to process, and my reading suggests that the Linux clients are faster at processing these types of work-units. Roberto Virga, the author of KSetiSpy, asserts:
“On average, the performance of the two clients [is] the same, since any advantage cumulated by the Windows client is lost at the first VLAR it gets.”
Note that Roberto is not only saying that the Linux clients are faster at processing VLAR’s (a view which is widely accepted) but that there is no overall speed advantage in choosing one client over the other (a view not so not so widely accepted probably due to the large number of Windows users and their bias) implying that the Windows clients are exceptionally slow at processing VLAR’s. To verify this without executing a large number of runs would require a typical VLAR work-unit. Searching the Web I was unable to find such a unit. I decided to leave the testing of this assertion to a later experiment. This would give me time to perhaps collect my own VLAR units. Whilst this omission weakens the result of this experiment, I think that it is acceptable given the infrequency of VLAR’s and the significant differences in processing times I discovered whilst using the amdmb work-unit described above.
The operating systems were chosen and setup to represent typical situations: a “Workstation” install of Red Hat 9, and Windows XP Professional SP-1. Both systems were fully patched using up2date and Windows Update. Windows XP was running McAfee Virus Scan and SetiSpy. Red hat 9 was logged into KDE and was running KSetiSpy. Both operating systems were not used for any other tasks during the testing. Both were installed on the following machine.
At the time of the experiment there was also a second Windows XP Professional computer available. This computer was also running McAfee Virus Scan and SetiSpy. I decided to process as many work-units as possible using the two Windows clients in an effort to determine the mean processing time for each client. Whilst a couple of days was not enough time to get a representative mean, it would at least yield a clue as to which was the fastest client. The second computer was as follows.
● AMDAthlon XP 2000+ (133MHz x 12.5 = 1.67GHz | 256kB L2 cache) ● Kingmax 512MB DDR SDRAM @ 166MHz (Set to ‘Turbo’!) ● EPoX 8K3A+ Motherboard (VIA KT333 Chipset)
Results
The times presented in the table below are in hours:minutes:seconds format.
v3.08
v3.03
Win XP Pro
5:25:42 5:16:46
5:14:35 4:52:32
Red Hat 9
5:58:03 5:44:49
5:19:26 5:29:02
Table 1: Time taken for clients to process amdmb work-unit (Athlon XP 1600+)
The times presented in the following table are in hours and the angle range (AR) is in degrees.
Windows XP Pro
v3.08
v3.03
AR
Time
AR
Time
1.902
2.844
0.927
3.077
1.061
3.278
0.702
3.230
0.428
3.585
0.435
3.239
0.614
3.541
0.652
3.233
0.664
3.346
0.726
3.208
0.428
3.584
0.613
3.276
0.426
3.612
0.793
3.295
6.521
2.852
0.429
3.248
1.219
2.900
0.427
3.253
0.703
3.458
0.665
3.148
0.427
3.589
0.008
3.607
Table 2: Time taken for Windows clients to process real work-units (Athlon XP 2000+)
Calculations & Discussion
For the next table the times are in hours:minutes:seconds format, and the percentage given in each case is the difference expressed as a percentage of the smaller amount.
v3.08
v3.03
Win XP Pro
Mean: 5:21:14 Range: 0:08:56 (2.8%)
Mean: 5:03:34 Range: 0:22:08 (7.4%)
Red Hat 9
Mean: 5:51:26 Range: 0:13:14 (3.8%)
Mean: 5:24:14 Range: 0:09:36 (3.0%)
Table 3: Means and ranges for clients to process amdmb work-unit (Athlon XP 1600+)
The results agree with my reading from the web. Note that the Windows 3.08 client is faster than the Linux 3.03 client for this particular work unit. Of greatest surprise is the significant variation in the time taken for the same client to process the same work-unit. I have tried to test the clients under normal “workstation” conditions. The larger than expected range implies that there is significant room for optimisation in the case of a dedicated SETI@home computer.
Percentage Differences in Time of the Clients (vertical faster than horizontal)
Lin 3.08
Lin 3.03
Win 3.08
Win 3.03
Lin 3.08
–8.5%
–9.4%
–15.8%
Lin 3.03
8.5%
–0.8%
–6.7%
Win 3.08
9.4%
0.8%
–5.8%
Win 3.03
15.8%
6.7%
5.8%
Table 4: Percentage differences in processing times for amdmb work-unit (Athlon XP 1600+)
From the above you can see that there is significant differences between the speeds of the various clients when processing the same work-unit.
The times presented in the following table are in hours and the angle range (AR) is in degrees.
Windows XP Pro
v3.08
v3.03
AR
Time
AR
Time
1.308
3.326
0.580
3.256
Table 5: Average AR’s and times for Windows clients to process real work-units (Athlon XP 2000+)
The results for the second part of the experiment (table 2) reveal an obvious correlation between AR and processing time. The table above shows that even when the 3.03 client is processing units of lower AR that it outperforms the 3.08 client.
Note that the last unit processed by the 3.03 client was a VLAR (AR = 0.008). Taking this unit from the data set and calculating the extra time taken as a percentage of the new average gives 12%. The results from the first part of the experiment suggest that the Windows 3.03 client is 6.7% faster than the Linux 3.03 client. Therefore if the means are representative, then for the claim as made by Roberto Virga above to be true, roughly every third work-unit would need to be a VLAR. This is clearly not the case. Of the 22 results listed only 1 was a VLAR.
I wasn’t expecting the variation shown by each of the clients when processing the same work-unit. A greater number of trials are needed using the work-unit from seti.amdmbpond.com.
A typical VLAR work-unit needs to be found to further test and compare the performance of all four of the clients.
A greater number of real trials should be conducted using all four of the clients to better ascertain real-world averages.